String
String 是最基本的 kv 结构。value 可以是字符串、数字、二进制数据,单个 value 可以容纳的最大数据长度是 512M
实现
String 的底层数据结构实现主要是 int 和 SDS(简单动态字符串)
- SDS 不仅可以保存文本数据,还可以保存二进制数据
- SDS 获取字符串长度的时间复杂度是 O(1),因为其使用 len 属性记录了长度
- SDS API 是安全的,拼接字符串不会造成缓冲区溢出。在拼接之前会检查 SDS 空间是否满足要求,空间不够时会自动扩容
字符串内部的编码有三种:int / raw / embstr
- 如果一个字符串表示的是整数值,并且这个整数值可以用 long 类型表示,那么字符串会将整数值保存在 ptr 属性中,并将编码设置为 int
- 如果保存的是一个字符串,并且长度小于 32 字节,那么将使用 SDS 来保存这个字符串,并将编码设置为 embstr
- 如果保存的是字符串,并且长度大于 32 字节,则使用 SDS 保存这个字符串,并将编码设置为 raw
不同的 redis 版本中 embstr 和 raw 的边界是不一样的
- redis 2.+ 是 32 字节
- redis 3.0-4.0 是 39 字节
- redis 5.0 是 44 字节
应用场景
- 缓存对象
- 常规计数
- 分布式锁
- 共享信息
List
List 是一个简单的字符串列表,按照插入顺序排序,可以向头部或者尾部添加元素。最大支持 2^32 - 1的列表长度
实现
- 3.2 版本之前:使用双向链表或压缩列表实现
- 如果列表元素小于 512 个,列表元素值小于 64 字节,使用压缩列表
- 不满足上述条件,使用双向链表
- 3.2 版本之后:使用 quicklist 实现
- 对比双向链表:链表每个节点都需要 prev 和 next 指针,内存消耗大
- 对比压缩列表:压缩列表紧凑但在数据量大时的插入删除成本高
quick list 实际是压缩列表和双向链表的混合体,它将双向链表按段切分,每一段使用压缩列表来紧凑存储,多个压缩列表之间使用双向指针串联
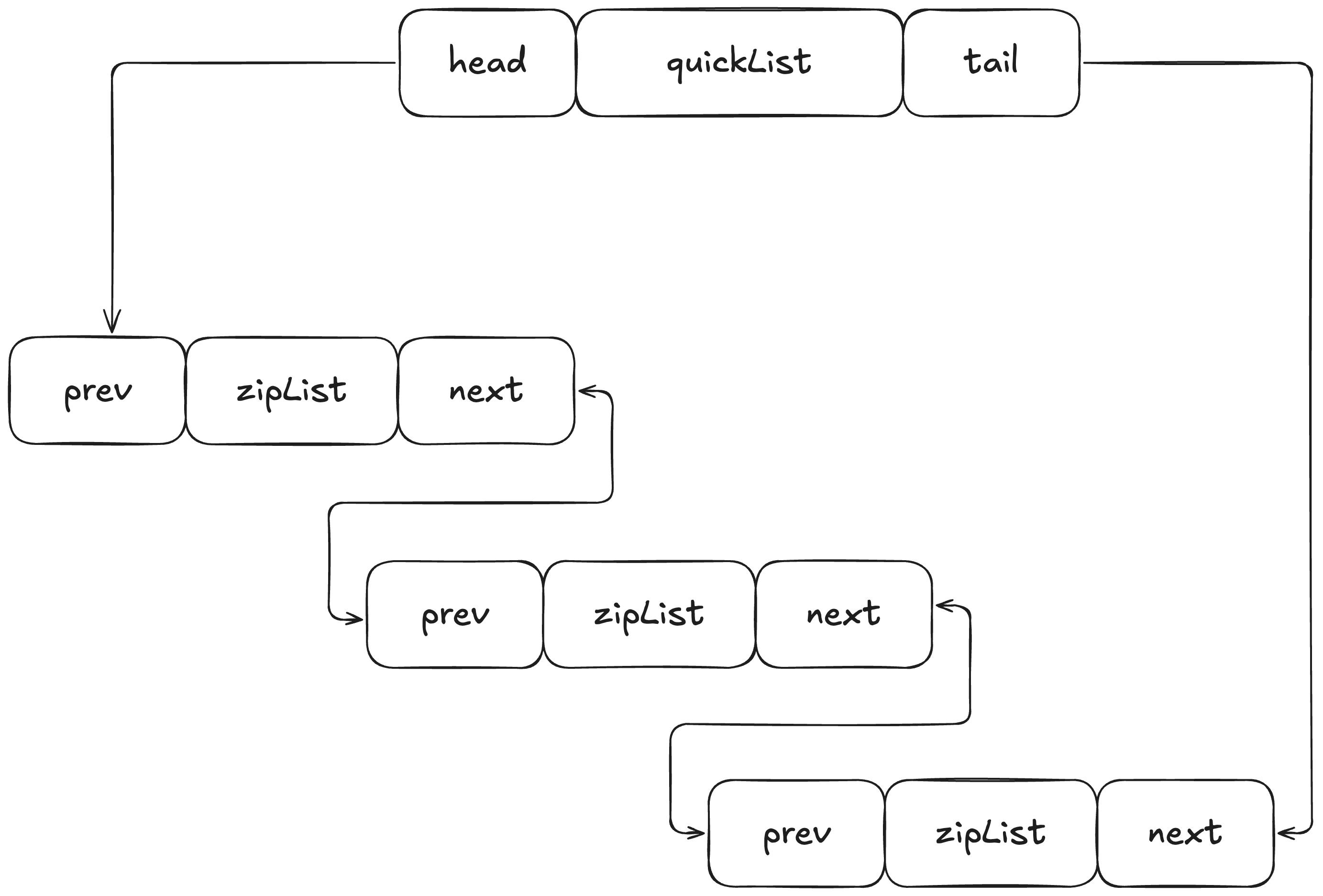
应用场景
- 队列
- 列表
Hash
实现
- 7.0 版本之前:使用压缩列表或哈希表实现
- 如果元素个数小于 50,所有值小于 64 字节,则使用压缩列表
- 不满条件则使用哈希表
- 7.0 之后:使用 listpack 替代压缩列表
- 压缩列表需要保存 prevlen(前一个 entry 长度),修改导致 prevlen 变化时,会导致连锁更新
- listpack 去掉了 prevlen,改用 encoding 记录当前 entry 大小
- 从后向前遍历时直接通过 encoding 计算位置
应用场景
- 缓存对象
- 缓存键值对
Set
Set 是无序并唯一的列表,一个集合最多存储 2^32-1 个元素,概念与数学中的集合类似,可以取交集、并集、差集等
Set vs List
- List 可以存储重复元素,Set 存储非重复元素
- List 元素有序,Set 无序
实现
使用哈希表或整数集合实现
- 如果元素都是整数,元素数量小于 512,则使用整数集合
- 否则使用哈希表
应用场景
- 存储不需要有序、唯一的数据
- 关注列表、点赞列表等
Sorted Set / ZSet
相比 Set 多了一个排序属性 score,每个元素由元素值与分值两部分构成
实现
使用压缩列表或(跳表 + 哈希表)实现
- 元素个数小于 128,且每个元素都小于 64 字节,则使用压缩列表
- 否则使用跳跃表
Redis 7.0 以上,压缩列表替换为 listpack
在使用跳跃表+哈希表时,哈希表主要用来保存 member 和 score 的对应关系,以保证可以以 O(1) 的复杂度查找 member 的 score
跳跃表则用来给 score 排序
应用场景
- 排行榜
- 排序
Bitmap
位图,是遗传连续的二进制数组,可以通过偏移量定位元素
实现
本身是用 String 类型实现的,可以看做 String 类型的特殊表现形式
应用场景
适合二值状态统计的场景(既元素取值只有 0 1 两种),在海量数据时,能有效节省内存空间
- 用户每日登录状态统计
- 用户连续签到统计
HyperLogLog
一种用于统计基数的数据集合类型(既统计一个集合中不重复的元素个数),但由于是基于概率完成的统计,并不是非常准确
既「提供不精确的大致去重计数」
应用场景
- 海量 UV 计数
GEO
用于存储位置信息
实现
使用 SortedSet 实现
使用 GeoHash 编码实现了经纬度到 score 的转换,按照 score 进行有序范围查找,即可实现「搜索附近」的需求
应用场景
- 搜索附近
Stream
Redis 5.0 为消息队列设计的数据类型,支持消息持久化、全局唯一 ID、ack 确认、消费组等
应用场景
- 消息队列
总结
常见的数据类型:
- String:常用于缓存、计数、分布式锁等
- List:列表数据存储
- Hash:对象缓存等
- Set:聚合计算等
- SortedSet/ZSet:排序场景
后续新增的一些消息类型:
- Bitmap:使用 String 实现,签到、用户登录状态统计等
- HyperLogLog:海量数据基数统计,如 UV 计数等
- GEO:存储地理位置
- Stream:消息队列