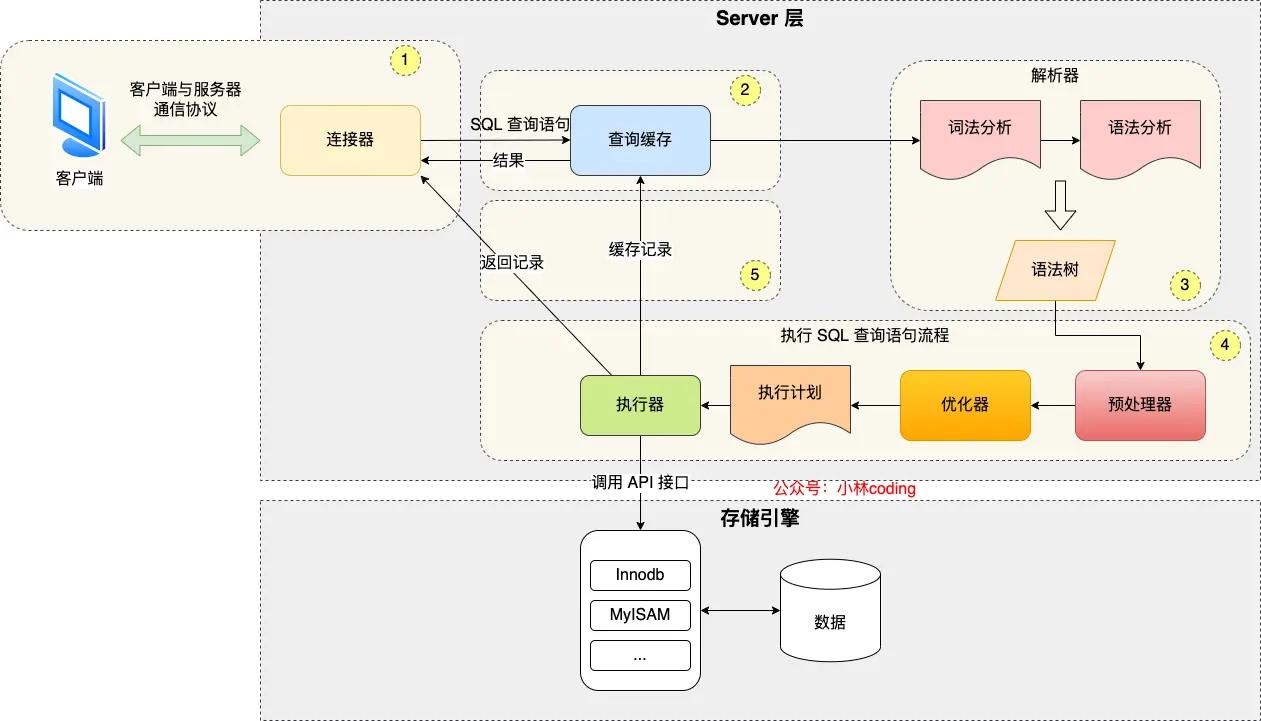
MySQL 架构分为两层:Server 层与存储引擎层
- Server 层:负责建立连接、分析和执行 SQL。MySQL 的大多数核心模块,例如连接器、查询缓存、解析器、预处理器、优化器、执行器等都在这里实现。另外,所有的内置函数(例如加密、日期等)和所有跨存储引擎的功能(存储过程、触发器、视图等)也都在这里实现。
- 存储引擎层:负责数据存储与提取,支持 InnoDB、MyISAM 等多个存储引擎,我们最常用的是 InnoDB,这也是 MySQL5.5 版本以来的默认存储引擎。索引的数据结构就是在存储引擎层实现的。
第一步 - 连接
与 MySQL 交互的第一步是建立连接,连接的过程需要经历 TCP 三次握手,连接成功之后会验证用户名和密码,并获取用户权限,此后连接上的所有操作都基于此时读到的权限进行判断
如果是在程序中进行交互,那么我们一般会在初始化时建立连接并保持。主流的 ORM 都支持连接池配置,会选择在合适的时间断开空闲连接。
第二步 - 查询缓存
事实上,在 MySQL 5.7 版本已经将查询缓存默认置为关闭,在 MySQL 8.0 版本删除了查询缓存功能。但有必要了解查询缓存是什么,以及为什么会被弃用
MySQL 为了提高查询效率,会对查询语句进行 Hash 计算,得到一个 Hash 值后,通过该值到查询缓存中匹配查询的结果。理想情况下,缓存能够极大的减轻查询压力,但在实际情况中却并非如此。
查询缓存要起到效果必须 Hash 值完全匹配,并且如果表中任意数据发生变更,则这张表的所有查询缓存都会失效,因此在实际业务中,查询缓存的有效率并不高。
另外为了维护缓存,需要再每次查询之后更新查询缓存,也会带来不小的性能开销。
第三步 - 解析 SQL
在正式执行查询之前,需要由解析器对 SQL 语句进行解析
词法分析
词法分析会根据输入的 SQL 语句,解析出关键字和非关键字。例如:
| 关键字 | 非关键字 | 关键字 | 非关键字 |
|---|---|---|---|
| select | username | from | userinfo |
语法分析
根据词法分析结果,解析器会判断输入的 SQL 语句是否符合语法规则。如果输入中有语法错误,就会在这个阶段报错。
如果语法没问题,则会构建一颗语法树,方便后边的模块获取 SQL 类型、表名、字段名、 where 条件等等。
第四步 - 执行 SQL
每天 Select 语句可以分为三个阶段:
- prepare 阶段,既预处理阶段
- optimize 阶段,既优化阶段
- execute 阶段,既执行阶段
预处理
预处理阶段会做以下事情:
- 检查查询中的表或者字段是否存在
- 将 select * 中的 * 扩展为表上的所有列
如果查询中的表或者字段不存在,就会在这个阶段报错。
优化
SQL 语句执行前,需要制定一个执行计划,以决定是否使用索引,以及使用哪个索引
可以使用 explain 来检查 SQL 语句的执行计划
执行
确认完执行计划之后,就由执行器来执行语句。这个过程中会与存储引擎进行交互。
总结
执行一条 SQL 期间发生了什么?
- 连接器:建立连接,校验用户身份
- 查询缓存:如果命中缓存则直接返回,否则继续向下执行。MySQL 8.0 已删除这个模块
- 解析 SQL:通过解析器对 SQL 进行词法分析和语法分析,构建语法书,方便后续模块读取病名、字段、语句类型
- 执行 SQL:
- 预处理:检查表或字段是否存在;将 select * 的 * 扩展为表上所有列
- 优化:基于查询成本考虑,选择查询成本最小的执行计划
- 根据计划执行 SQL 语句,从存储引擎读取记录,返回给客户端
架构图(来自xiaolincoding.com):