
数据库记录是按照「行」来存储的,但是数据库的读取并不以「行」为单位,否则一次读取只能处理一行数据,效率会非常低
因此,InnoDB 的数据是以「数据页」为单位来读写的。也就是说,当需要读取一条数据的时候,是以页为单位,将其整体读入内存。
InnoDB 的 IO 操作的最小单位是页,InnoDB 数据页的默认大小是 16kb,意味着数据库每次读写都是以 16kb 为单位的
- 一次最少读取 16kb 的内容到内存中
- 一次最少把内存中的 16kb 内容刷新到磁盘中
一个数据页包含七个部分:
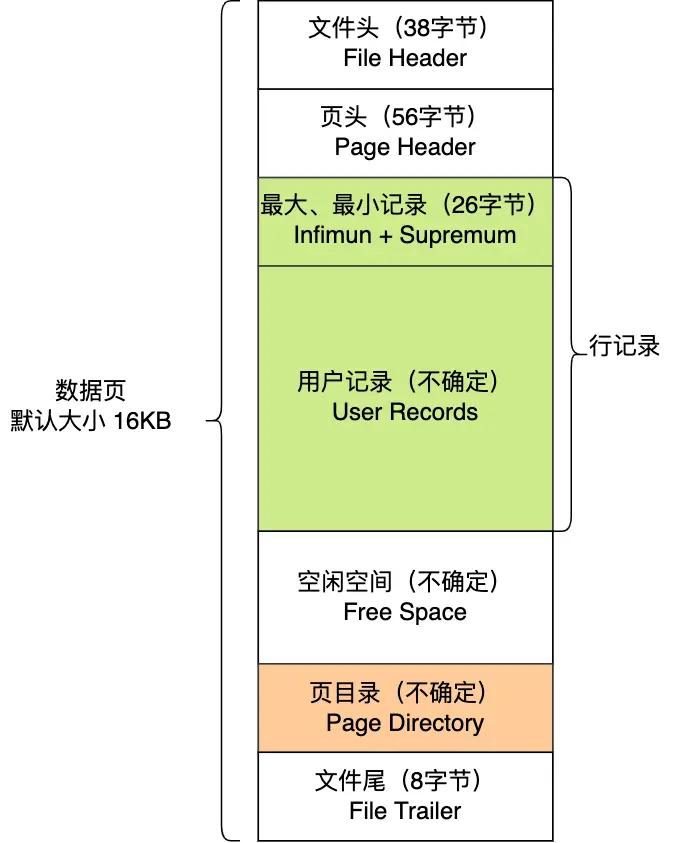
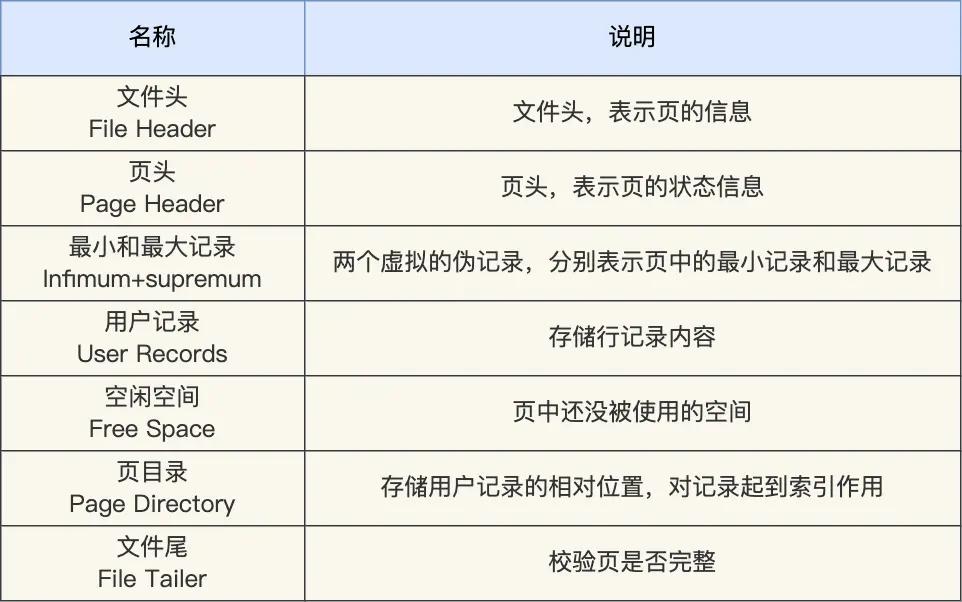
这七个部分的作用如下图:
在文件头中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向链表:
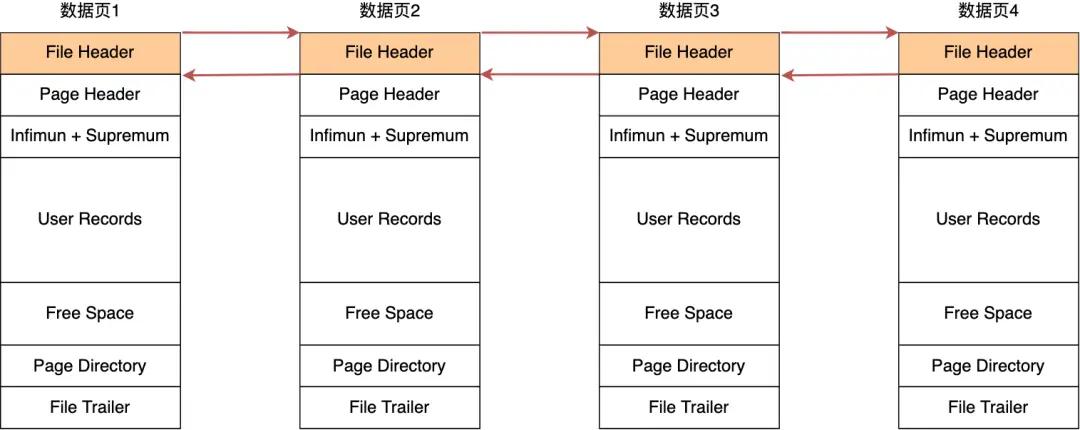
采用链表的结构的优点:
- 物理结构与逻辑组织分离,数据页在磁盘上的物理存储位置可以是随机不连续的,通过双向指针将这些分散的页在逻辑上连接成双向链表
- 插入新数据时,不需要移动或重排现有的数据页。只需调整相关页的指针,即可将新野插入逻辑序列的正确位置。删除数据时同理
同一个数据页中的记录会按照「主键顺序」组成单向链表。单向链表的特点是插入、删除非常方便,但是检索效率不高,只能由头结点开始向后检索。
因此数据页中有一个「页目录」,起到记录的索引作用,示例结构如下图:
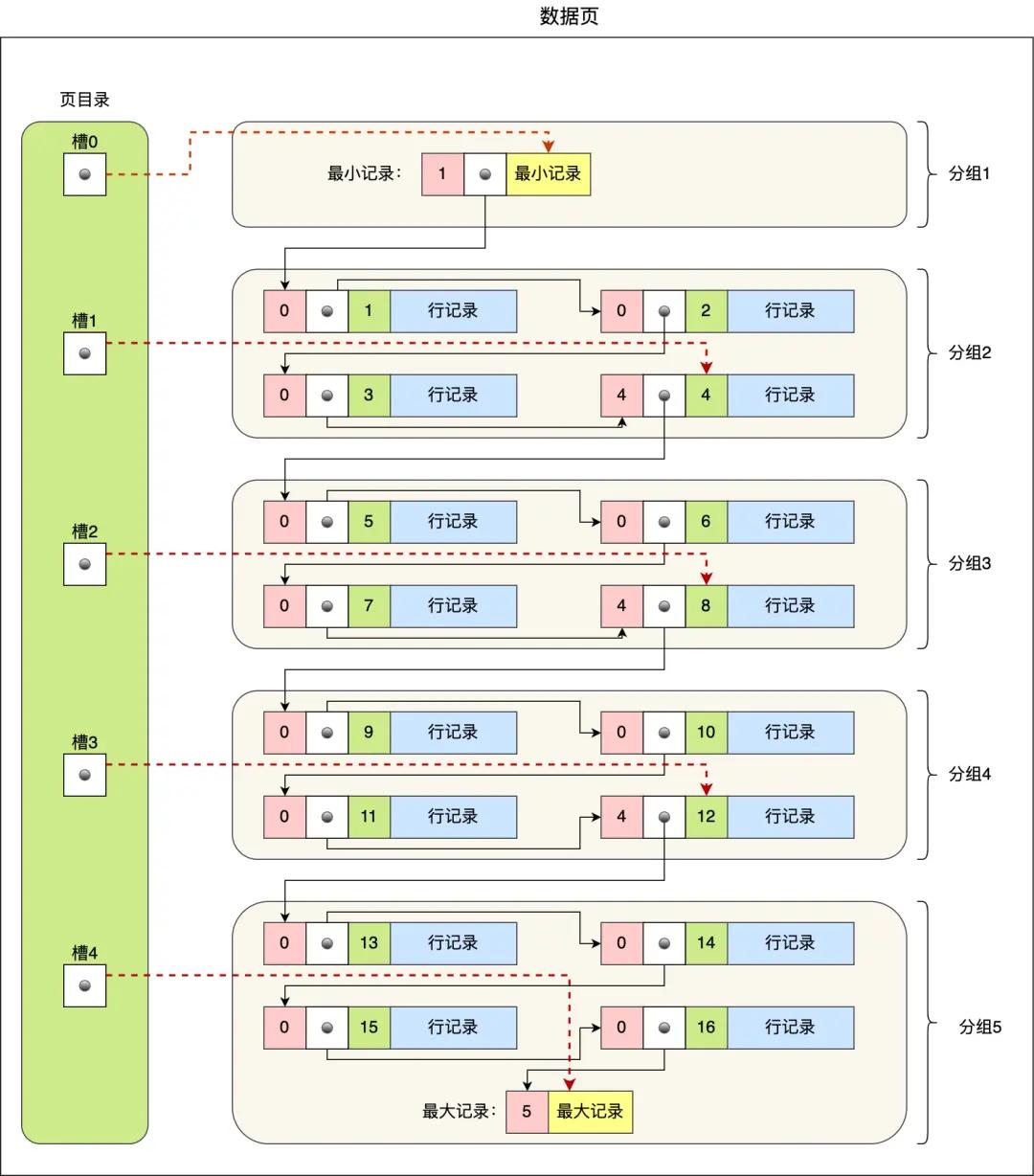
页目录创建的过程如下:
- 将所有记录划分为几个组,这些记录包括最小记录和最大记录,但不包括标记为已删除的记录
- 每个记录组的最后一条记录就是组内最大的记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图粉红色字段)
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一条记录
从图中可以看出,页目录就是由多个槽组成的,槽相当于分组记录的索引。由于记录是按照「主键值」从小到大顺序排列的,所以当通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽,定位到槽后,再遍历槽内的所有记录,找到对应的记录。